Cluster Maintenance
In this section, we will discuss cluster maintenance related topics. Operating system upgrades, also the implications of losing a node in the cluster. Or when you take a node out of the cluster for maintenance. E.g. for applying patches or upgrading the OS. Then we will discuss Cluster Upgrade but before we will tackle Kubernetes releases and versioning.
Also, best practices for upgrading Kubernetes When to upgrade, and what version to upgrade to. End to end upgrade to a cluster. With live applications.
Finally, we will discuss Backup and Restore strategies for Kubernetes clusters. Including etcd backup and restore. And how to backup and restore the entire cluster. Disaster recovery strategies.
OS Upgrades
Taken down nodes as part of your cluster for maintenance. E.g. for applying patches or upgrading the OS. This is a common task in a production environment. You need to make sure that your applications are still running and that the cluster is still healthy.
If the node came back online immediately, the kubectl process starts and the pods come back online. But if the node is down for more than five minutes, then the pods are terminated from that node. Kubernetes will consider them as dead. If the pods were a part of a replicaset, then they are recreated on other nodes. And when the node come back online after the pod eviction time, it comes up blank. But any pods that were running on that node and without a replicaset will be just gone.
A more safer way is to: drain the node before taking it down. kubectl drain <node-name>. This will evict all the pods from the node. The pods will be gracefully terminated. And recreated on other nodes. This node will be marked as Unschedulable. No new pods will be scheduled on this node. Until you specifically remove this restriction.
After you finish the maintenance, you can uncordon the node. kubectl uncordon <node-name>. This will allow the pods to be scheduled on this node again.
The pods that were removed, will not automatically fall back to the node.
You can also cordon the node. kubectl cordon <node-name>. This will prevent new pods from being scheduled on this node. But the existing pods will continue to run.
kubectl get po -o custom-columns=POD:.metadata.name,NODE:.spec.nodeName
POD NODE
blue-667bf6b9f9-8kmlj node01
blue-667bf6b9f9-dqkl7 controlplane
blue-667bf6b9f9-pzpmx node01
kubectl drain <node-name> --ignore-daemonsets
node/node01 cordoned
Warning: ignoring DaemonSet-managed Pods: kube-flannel/kube-flannel-ds-pmhzp, kube-system/kube-proxy-plbns
evicting pod default/blue-667bf6b9f9-pzpmx
evicting pod default/blue-667bf6b9f9-8kmlj
pod/blue-667bf6b9f9-pzpmx evicted
pod/blue-667bf6b9f9-8kmlj evicted
node/node01 draine
kubectl get po -o custom-columns=POD:.metadata.name,NODE:.spec.nodeName
POD NODE
blue-667bf6b9f9-2vthg controlplane
blue-667bf6b9f9-dqkl7 controlplane
blue-667bf6b9f9-l6tk7 controlplane
kubectl uncordon node01
node/node01 uncordoned
Kubernetes Releases
When you install a Kubernetes cluster, we install a specific version of Kubernetes. You can see that when you run kubectl get nodes.
Kubernetes release versions follows three parts: Major.Minor.Patch. Every few month a minor version is released. With new features and functionalities. Patches are released more often. With critical bug fixes and security patches.
Just like any popular software, Kubernetes follows a standard software release versioning procedure. The first Major version was v1.0 in July 2015. The current latest is here.
Whatever we have seen between v1.0 and v1.29 are STABLE releases.
Apart from the stable releases, there are also ALPHA and BETA releases. All the bug fixes and improvements first go into a release tagged ALPHA. In this release, the feature are disabled by default and maybe buggy. Then from there they make their way to the BETA release. Where the features are well tested. And the new features are enabled by default. Finally, they make their way to the main STABLE release.
Download the desired version from github kubernetes releases page. Download the kubernetes.tar.gz file. Extract it to find executables for all k8s components. The downloaded pkg when extracted has all the control plain components. All of them of the SAME version. But, remember there are other components within the control plane that do not have the same version. E.g. etcd and coredns.
The etcd cluster and coredns servers have their own versions as they are separate projects. The release notes provides information about the supported versions of externally dependent components like etcd and coredns.
Api References
Cluster Upgrade Process
We will keep dependencies for external components like etcd and coredns aside for now. And focus on the core control plane components. E.g.: kube-apiserver, kube-controller-manager, kube-scheduler, kube-proxy, kubelet and kubectl.
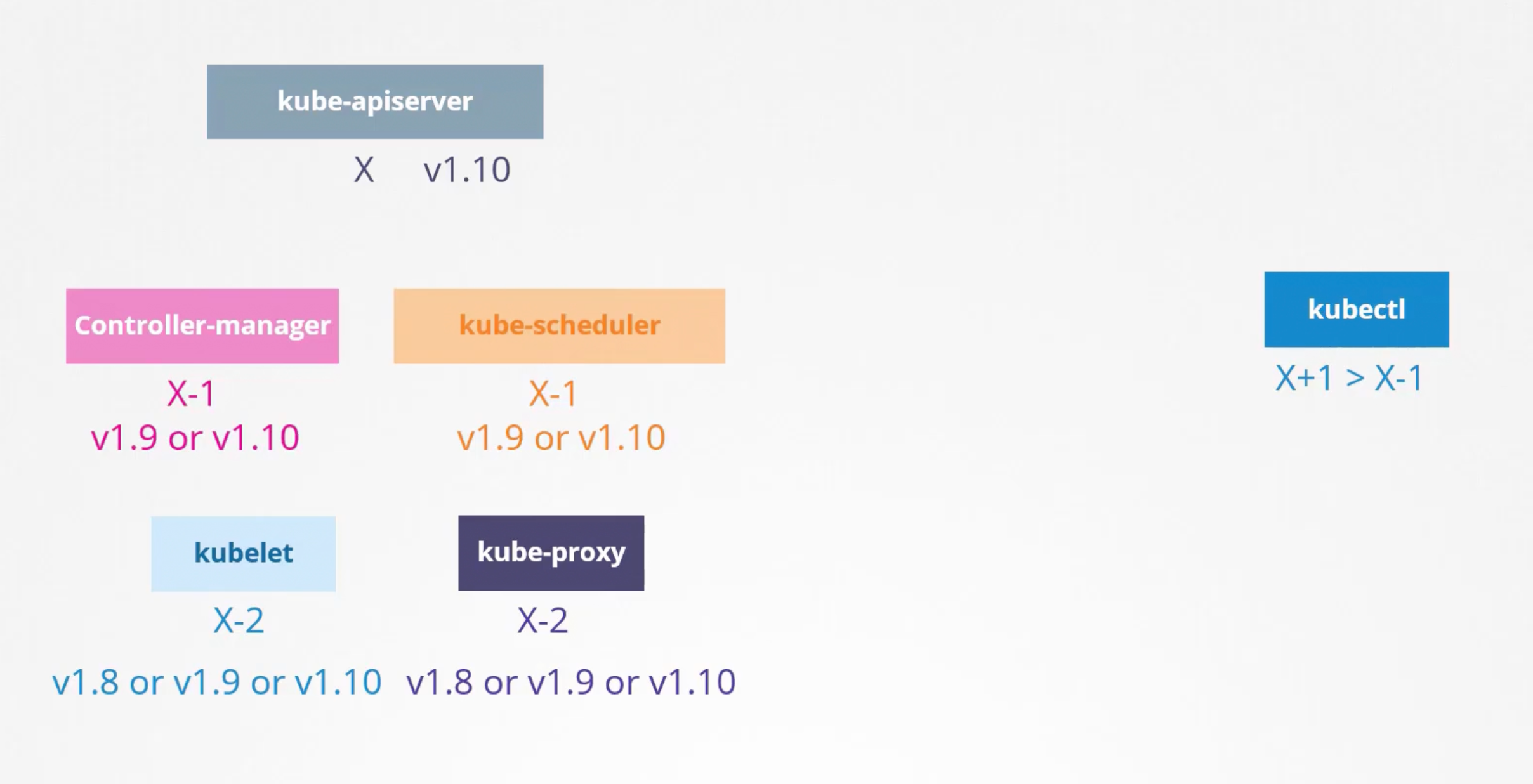
Is it mandatory for all these components to be of the same version?
No, it is not. But since the kube-apiserver is the primary component, which all other components talk to. None of the other components should ever be at a version higher than the kube-apiserver. The controller-manager, scheduler, can be at one version lower. The kubelet and kube-proxy can be at two versions lower.
This is not the case with kubectl. It can be at any version. This permissible skew in versions allows us to carry out live upgrades. We can upgrade component by component if we wanted.
When to Upgrade
Say you are running v1.10 and kubernetes releases v1.11 and v1.12. At any time kubernetes supports only up to the recent three minor versions. Before the release of v1.13, it would be a good time to upgrade your cluster to the next release.
So how do we upgrade? Do we upgrade directly from v1.10 to v1.13?
No, The recommended approach is to upgrade one minor version at a time.
-
API Compatibility: Kubernetes maintains API compatibility within minor versions. Upgrading one minor version at a time greatly reduces the risk of breaking changes that could disrupt your applications due to removed or modified API objects.
-
Feature Deprecation: Kubernetes has a deprecation policy. While features might be deprecated over multiple releases, you may encounter removed features with larger jumps, impacting your manifests. Gradual upgrades give you time to adapt.
-
Component Compatibility: Different Kubernetes components (kubelet, kube-apiserver, etc.) might have version skew tolerances. Gradual upgrades help you stay within those tolerances for smoother operation.
-
Bug Mitigation: Sometimes bug fixes and security patches are backported into supported minor versions. Sticking to one-step upgrades increases your chances of including those fixes without the risk of bigger changes.
-
Easier Troubleshooting: If something goes wrong with an upgrade, a smaller version change makes it easier to isolate the cause and potentially roll back.
- Read Release Notes: Meticulously review the release notes for v1.12, v1.13, and v1.14 to identify:
- API deprecations/removals that might impact your deployments.
- Breaking changes in features you use.
- Important bug fixes or security patches you'd want to include.
- Backup: Before starting the upgrade, ensure you have a backup of your cluster state, including etcd data. While the risk of significant data loss during a single minor version Kubernetes upgrade is relatively low, taking backups is always a wise precaution.
- Iterative Updates: Upgrade to 1.12 first, test thoroughly, then to 1.13, and so on. This might require updating manifests to adapt to changes if needed.
- Testing: Have a robust testing plan at each upgrade stage. Include regression testing for your applications and cluster functionality to catch potential breakages earlier.
Additional Considerations
- Add-on Compatibility: Check compatibility of any add-ons (ingress controllers, storage providers, etc.) with the target Kubernetes version.
- Downtime Strategy: Depending on your setup (control plane redundancy, etc.), prepare for potential downtime during control plane upgrades.
- etcd Backups:
- etcd is Kubernetes' distributed key-value store. It contains the entire state of your cluster.
- Absolutely Essential: Back up etcd before upgrading, as this is your most critical data store for restoring the cluster if anything goes severely wrong.
- Persistent Volumes (PVs):
- If your applications rely on data stored in PVs, your backup strategy depends on the type of storage the PVs use:
- Cloud Providers: Often, cloud-provided storage has built-in snapshot/backup capabilities. Make sure you have recent snapshots.
- Network Storage Solutions: Consult your storage solution's documentation for backup procedures.
- If your applications rely on data stored in PVs, your backup strategy depends on the type of storage the PVs use:
- ConfigMaps and Secrets (Optional):
- These typically store application configurations and sensitive data.
- Recommended but not always critical: If they aren't managed outside the cluster or through GitOps, back these up too. Tools like Velero can help.
Why Backups Might Be Less Critical for Minor Upgrades
- API Compatibility: Minor version upgrades don't tend to break API objects dramatically.
- Data Plane Focused: Minor upgrades usually focus on upgrading components rather than changing fundamental data structures.
Still, Better Safe Than Sorry
- Peace of mind: Backups provide a safety net if
unforeseen issues pop up. - Quick Rollbacks: With backups, a problematic upgrade is more easily addressed by rolling back.
Process Matters Too:
- Automated Upgrades: Tools like
kubeadmoften have integrated backup/rollback capabilities. - Well-Tested Cluster Setup: If you have extensive testing and confidence in your configuration, the risk is further reduced.
Summary:
While the need for full backups before each minor upgrade might be debatable based on your setup and risk tolerance, backing up etcd is non-negotiable. Consider backing up other components for an extra layer of resilience.
The upgrade process depends on how your cluster was set up.
If it is a managed cluster, then the cloud provider will take care of the upgrade with just a few clicks.
If you used tools like kubeadm, then the tool can help you plan and execute the upgrade.
If you deployed the cluster from scratch, then you manually upgrade the different components of the cluster yourself.
In this section we will discuss how to upgrade a cluster that was set up using kubeadm. So you have a cluster with master and worker nodes. Running in production. The nodes and the components are running at v1.10. Upgrading the cluster involves two major steps:
- Upgrading the control plane.
- Upgrading the worker nodes.
While the master is being upgraded, the control plane components such as kube-apiserver, kube-scgeduler and kube-controller-manager go down briefly. Note that the master going down does not affect the worker nodes. But all management operations are down. You can not access the cluster using kubectl or other kubernetes APIs. The controller manager does not function either, so if a pod was to fail, it would not be restarted. But as long as the nodes are up, the pods will continue to run. Now the master node is at v1.11. The worker nodes are still at v1.10. The next step is to upgrade the worker nodes.
There are different strategies to upgrade the worker nodes. The most common approach is to upgrade one node at a time. While we are doing so just move the workloads to other nodes.
Another approach is to upgrade all the worker nodes at once. This is a risky approach. But if you have a large number of nodes, then this approach might be faster. But, it will cause downtime for the applications running on the cluster.
Also another interesting approach is to add new nodes with the new version. Can be easily done in cloud environments. And decommission the old nodes. Move workloads to the new nodes. This approach is the least risky. But it is also the most expensive.
Example
kubeadm has an upgrade command that can help you upgrade the control plane components. kubeadm upgrade plan will show you the plan. E.g. current cluster version, kubeadm version, and the latest stable version. Then it lists all the control plane components and their versions.
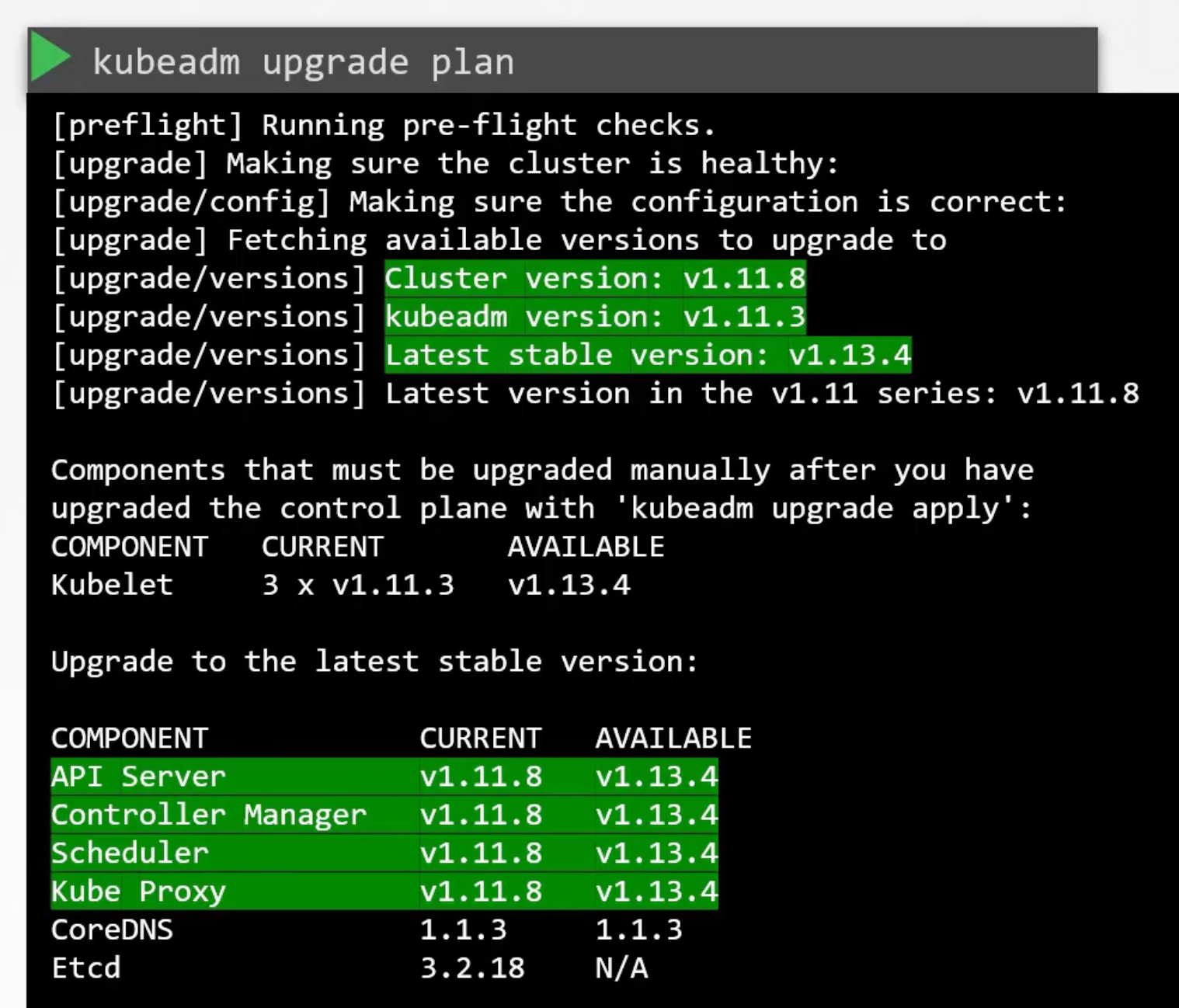
Also, tells you that after you upgrade the control plane, you need to upgrade the kubelet manually. Remember kubeadm does not install or upgrade kubelet.
Finally it gives you the command to upgrade the cluster kubeadm upgrade apply v1.13.4. And notifies you to first upgrade the kubeadm to v1.13.4.
The kubeadm tool also follows the same software versioning as kubernetes.
We go one minor version at a time, highly dependant on your cluster setup. But always start with control plane nodes then worker nodes:
- Make sure you are using
pkgs.k8s.ioas package repository. Theapt.kubernetes.ioandyum.kubernetes.ioare deprecated. Then doapt-get update.Both on ALL the master and worker nodes. - Upgrade kubeadm on the master node.
- Upgrade the control plane with
kubeadm. - Drain the nodes first, then upgrade the kubelet and kubectl on Master node. And restart kubelet service. Finally, uncordon the node.
- Repeat the above steps for all control plane nodes. Just the normal above steps but run
kubeadm upgrade nodeinstead ofapply. - Next Worker Nodes, one at a time.
- Drain the node.
- Upgrade kubeadm on the worker node.
- Upgrade kubelet on the worker node.
- Update node configuration for the new kubelet version using
kubeadm. - Restart kubelet service.
- Uncordon the node.
Repeat for all worker nodes.
You may or may not have kubelet running on the master node. If cluster setup with by kubeadm then you have kubelet running on the master node as it is running control plane components as pods. But if your setup was from scratch, then you will not see the master node in the output of
kubectl get nodes.
# ---> Step One: Prepare repository
cat /etc/*release* # check the OS version, say Ubuntu
# `WARNING` do NOT forget to change the version in the following commands, there is different pkg repo for each minor version. E.g. 1.29 if you are at 1.28 and want to reach 1.29.
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
apt-get update
# You need to determine which patch version you want to upgrade to.
apt update
apt-cache madison kubeadm # 1.29.3-1.1
# ---> Step Two: Upgrade kubeadm on the master node
apt-get upgrade -y kubeadm=1.12.0-00
## Or
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm='1.29.3-1.1' && \
apt-mark hold kubeadm
## Verify the version
kubeadm version
# ---> Step Three: Upgrade the control plane components
kubeadm upgrade plan # shows the plan
kubeadm upgrade apply v1.12.0 # pulls the necessary images and upgrades the control plane
## Or
kubeadm upgrade apply v1.29.3
## Verify the version
kubectl get nodes # shows the master node at v1.11.3 cuz this is the o/p of kubelet, not api-server itself.
# `WARNING` at this step you might need to upgrade your CNI provider plugin. Check addons page to find if your CNI provider and see wether additional upgrade steps are required. This step is not required on additional control plane nodes if the CNI provider runs as a DaemonSet.
# ---> Step Four: Upgrade the kubelet on the master node
kubectl drain <node-name> --ignore-daemonsets
apt-get upgrade -y kubelet=1.12.0-00
## Or
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet='1.29.3-1.1' kubectl='1.29.3-1.1' && \
apt-mark hold kubelet kubectl
# Restart kubelet
systemctl daemon-reload
systemctl restart kubelet
# Verify the version
kubectl get nodes # shows the master node at v1.12.0
# Uncordon the node
kubectl uncordon <node-name>
# ---> Step Six: Worker Nodes. `Correct STEPS` Upgrade kubeadm, update node, drain node, upgrade kubelet, restart kubelet, uncordon node.
kubectl drain <node-name>
# SSH to node01
apt-get upgrade -y kubeadm=1.12.0-00
apt-get upgrade -y kubelet=1.12.0-00
## Or
# `WARNING` you usually do not have kubectl on worker nodes.
apt-mark unhold kubeadm kubelet kubectl && \
apt-get update && apt-get install -y kubeadm='1.29.3-1.1' kubelet='1.29.3-1.1' kubectl='1.29.3-1.1' && \
apt-mark hold kubeadm kubelet kubectl
# Update the kubelet configuration
kubeadm upgrade node config --kubelet-version v1.12.0
## Or
kubectl upgrade node
# Restart kubelet
systemctl daemon-reload
systemctl restart kubelet # Node now is up with the new software version
# Uncordon the node
kubectl uncordon <node-name>
Full Example
In this example we have a cluster at v1.28.0 and we want to upgrade it to v1.29.3. The cluster was setup with kubeadm. One master node and One worker node.
Step One
Make sure you are using pkgs.k8s.io as package repository. The apt.kubernetes.io and yum.kubernetes.io are deprecated. Then do apt-get update.
Both on ALL the master and worker nodes.
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
apt-get update
You need to determine which patch version you want to upgrade to. So in master node run:
apt update
apt-cache madison kubeadm
Step Two
Upgrade kubeadm on the master node.
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm='1.29.3-1.1' && \
apt-mark hold kubeadm
Verify the version
kubeadm version
Step Three
Upgrade the control plane components. Plan first then apply.
kubeadm upgrade plan
kubeadm upgrade apply v1.29.3
Verify the version using:
kubectl get nodes
The above command shows the master node at v1.28.0 because this is the output of kubelet, not api-server itself.
Step Four
Upgrade the kubelet on the master node. First drain the node. Then upgrade the kubelet. Restart kubelet service. Finally, uncordon the node.
kubectl drain <node-name> --ignore-daemonsets
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet='1.29.3-1.1' kubectl='1.29.3-1.1' && \
apt-mark hold kubelet kubectl
systemctl daemon-reload
systemctl restart kubelet
kubectl get nodes
kubectl uncordon <node-name>
Step Five
If any additional control plane nodes are present, repeat the above steps for all control plane nodes. Just the normal above steps but run kubeadm upgrade node instead of apply.
Step Six
Next Upgrade Worker Nodes, one at a time:
- Drain the node.
- Upgrade kubeadm on the worker node.
- Upgrade kubelet on the worker node.
- Update node configuration for the new kubelet version using kubeadm.
- Restart kubelet service.
- Uncordon the node.
- Repeat for all worker nodes.
kubectl drain <node-name>
ssh <node-name>
apt-mark unhold kubeadm kubelet kubectl && \
apt-get update && apt-get install -y kubeadm='1.29.3-1.1' kubelet='1.29.3-1.1' kubectl='1.29.3-1.1' && \
apt-mark hold kubeadm kubelet kubectl
kubectl upgrade node
## Or
kubeadm upgrade node config --kubelet-version v1.29.3
systemctl daemon-reload
systemctl restart kubelet
kubectl uncordon <node-name>
Backup and Restore
In this section we will discuss the various backup and restore methodologies for Kubernetes clusters.
What should you consider backing up in a k8s cluster?! We know that ETCD cluster is where all cluster-related information is stored. And if your applications are configured to use persistent volumes, then you should also consider backing up the persistent volumes.
Declarative way is the go for Resource Configurations. Use version control.
What if objects were created using imperative way?!
Query kube-api-server is a better approach, using the kubectl or by accessing the API directly. And save all resource configurations for all objects created on the cluster. As a copy.
E.g. kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml This is just for a small resource group. There are many other resource groups that must be considered.
There are tools like ARK by Heptio, Now called Velero that can help you backup and restore your cluster.
Etcd
The etcd cluster stores information about the state of our cluster. It stores information about the nodes, pods, services, and all other resources in the cluster.
Instead of backing up resources as before, we can backup the etcd cluster itself. The etcd cluster is hosted on the master nodes. While configuring etcd we can specify the location where all the data would be stored --data-dir=/var/lib/etcd. That is the directory that can be configured to be backed up. By your backup tool.
Etcd also comes with a built-in snapshot solution. You can take a snapshot of the etcd database. And store it in a safe location just run ETCDCTL_API=3 etcdctl snapshot save snapshot.db.
You can view the status of the backup using ETCDCTL_API=3 etcdctl snapshot status snapshot.db.
To restore the etcd cluster from a snapshot, you need to:
- Stop the kube-api-server, as the restore process will require you to restart the etcd cluster. And the kube-api-server depends on it.
- Run
ETCDCTL_API=3 etcdctl snapshot restore snapshot.db --data-dir /var/lib/etcd-from-backup.
The restore will initialize a new cluster configuration and configures the members of etcd as new members of the new cluster. This is to prevent a new member from accidentally joining an existing cluster. On running this command a new data directory is created. We then configure the etcd configuration file to point to this new data directory. And start the etcd cluster. --data-dir=/var/lib/etcd-from-backup. Then systemctl daemon-reload and service etcd restart. Finally, service kube-apiserver start.
THe cluster should be back now in the original state.
With all etcd commands remember to specify the certificate files for authentication. And the endpoint to the etcd cluster and the cert certificate and the etcd server certificate and key. As follows:
ETCDCTL_API=3 etcdctl snapshot save snapshot.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/etcd/ca.crt \
--cert=/etc/etcd/etcd-server.crt \
--key=/etc/etcd/etcd-server.key
We have discussed two options a backup using etcd and a backup by querying the kube-apiserver. Both have their own pros and cons. If you are using a manged k8s environment, then at times you might not have access to the etcd cluster. In that case, you can use the kube-apiserver to backup the resources.
etcdctl is a command line client for etcd.
In all our Kubernetes Hands-on labs, the ETCD key-value database is deployed as a static pod on the master. The version used is v3.
To make use of etcdctl for tasks such as back up and restore, make sure that you set the ETCDCTL_API to 3.
You can do this by exporting the variable ETCDCTL_API prior to using the etcdctl client. This can be done as follows export ETCDCTL_API=3.
On the Master Node:
export ETCDCTL_API=3
etcdctl version
To see all the options for a specific sub-command, make use of the -h or –help flag. For example, if you want to take a snapshot of etcd, use etcdctl snapshot save -h and keep a note of the mandatory global options.
Since our ETCD database is TLS-Enabled, the following options are mandatory:
--cacert: verify certificates of TLS-enabled secure servers using this CA bundle.--cert: identify secure client using this TLS certificate file.--endpoints=[127.0.0.1:2379]: This is the default as ETCD is running on master node and exposed on localhost 2379.--key: identify secure client using this TLS key file.
For a detailed explanation on how to make use of the etcdctl command line tool and work with the -h flags, check out the solution video for the Backup and Restore Lab.
Extra:
server certificate:--cert-file=/etc/kubernetes/pki/etcd/server.crtand called--certin the etcdctl commands.etcd ca certificate:--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crtand called--cacertin the etcdctl commands.
Backup Example
controlplane ~ ➜ kubectl get pod etcd-controlplane -n kube-system -o json | jq '.spec.containers[0].command'
[
"etcd",
"--advertise-client-urls=https://192.19.224.9:2379",
"--cert-file=/etc/kubernetes/pki/etcd/server.crt",
"--client-cert-auth=true",
"--data-dir=/var/lib/etcd",
"--experimental-initial-corrupt-check=true",
"--experimental-watch-progress-notify-interval=5s",
"--initial-advertise-peer-urls=https://192.19.224.9:2380",
"--initial-cluster=controlplane=https://192.19.224.9:2380",
"--key-file=/etc/kubernetes/pki/etcd/server.key",
"--listen-client-urls=https://127.0.0.1:2379,https://192.19.224.9:2379",
"--listen-metrics-urls=http://127.0.0.1:2381",
"--listen-peer-urls=https://192.19.224.9:2380",
"--name=controlplane",
"--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt",
"--peer-client-cert-auth=true",
"--peer-key-file=/etc/kubernetes/pki/etcd/peer.key",
"--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt",
"--snapshot-count=10000",
"--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt"
]
controlplane ~ ➜ ETCDCTL_API=3 etcdctl snapshot save /opt/snapshot-pre-boot.db \
> --endpoints=https://127.0.0.1:2379 \
> --cacert=/etc/kubernetes/pki/etcd/ca.crt \
> --cert=/etc/kubernetes/pki/etcd/server.crt \
> --key=/etc/kubernetes/pki/etcd/server.key
Snapshot saved at /opt/snapshot-pre-boot.db
controlplane ~ ➜
Restore Example
ETCDCTL_API=3 etcdctl snapshot restore /opt/snapshot-pre-boot.db \
--data-dir /var/lib/etcd-from-backup \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
In this case, we are restoring the snapshot to a different directory but in the same server where we took the backup (the controlplane node) As a result, the only required option for the restore command is the --data-dir.
Next, update the /etc/kubernetes/manifests/etcd.yaml:
We have now restored the etcd snapshot to a new path on the controlplane - /var/lib/etcd-from-backup, so, the only change to be made in the YAML file, is to change the hostPath for the volume called etcd-data from old directory (/var/lib/etcd) to the new directory (/var/lib/etcd-from-backup).
volumes:
- hostPath:
path: /var/lib/etcd-from-backup
type: DirectoryOrCreate
name: etcd-data
With this change, /var/lib/etcd on the container points to /var/lib/etcd-from-backup on the controlplane (which is what we want).
When this file is updated, the ETCD pod is automatically re-created as this is a static pod placed under the /etc/kubernetes/manifests directory.
As the ETCD pod has changed it will automatically restart, and also kube-controller-manager and kube-scheduler. Wait 1-2 to mins for this pods to restart. You can run the command: watch "crictl ps | grep etcd" to see when the ETCD pod is restarted.
If the etcd pod is not getting Ready 1/1, then restart it by kubectl delete pod -n kube-system etcd-controlplane and wait 1 minute.
This is the simplest way to make sure that ETCD uses the restored data after the ETCD pod is recreated. You don't have to change anything else.
If you do change --data-dir to /var/lib/etcd-from-backup in the ETCD YAML file, make sure that the volumeMounts for etcd-data is updated as well, with the mountPath pointing to /var/lib/etcd-from-backup (THIS COMPLETE STEP IS OPTIONAL AND NEED NOT BE DONE FOR COMPLETING THE RESTORE)
Multi Cluster Setup
# Get number of clusters
kubectl config get-contexts | grep -v NAME | wc -l # Get number of clusters
kubectl config view # Get all clusters or entire kubeConfig file
kubectl config use-context cluster1
kubectl config use-context cluster2
# Get current context
kubectl config current-context
sudo find /etc/systemd/system/ -name etcd.service
ETCDCTL_API=3 etcdctl member list \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/etcd/pki/ca.pem \
--cert=/etc/etcd/pki/etcd.pem \
--key=/etc/etcd/pki/etcd-key.pem
External ETCD
ps -ef | grep etcd
# `--advertise-client-urls` ---> `--endpoints`
# `--cert-file` ---> `--cert`
# `--key-file` ---> `--key`
# `--trusted-ca-file` ---> `--cacert`
--data-dir=/var/lib/etcd-data
--advertise-client-urls https://192.22.104.9:2379
--cert-file=/etc/etcd/pki/etcd.pem
--key-file=/etc/etcd/pki/etcd-key.pem
--trusted-ca-file=/etc/etcd/pki/ca.pem
# back up from /opt/cluster2.db
ETCDCTL_API=3 etcdctl snapshot restore /opt/cluster2.db \
--data-dir /var/lib/etcd-data-new \
--endpoints=https://192.22.104.9:2379 \
--cacert=/etc/etcd/pki/ca.pem \
--cert=/etc/etcd/pki/etcd.pem \
--key=/etc/etcd/pki/etcd-key.pem
# Check permission
ls -l /var/lib/
chown -R etcd:etcd /var/lib/etcd-data-new
# Update the etcd service file
sudo find /etc/systemd/system/ -name etcd.service
vi /etc/systemd/system/etcd.service
# restart etcd
systemctl daemon-reload
systemctl restart etcd
# Restart kube-apiserver, scheduler and kubelet
kubectl delete po -n kube-system kube-apiserver-controlplane kube-scheduler-controlplane
ssh controlplane
systemctl restart kubelet
Staked ETCD
kubectl describe pods -n kube-system <etcd-pod-name>
# Search for:
# `--advertise-client-urls` ---> `--endpoints`
# `--cert-file` ---> `--cert`
# `--key-file` ---> `--key`
# `--trusted-ca-file` ---> `--cacert`
ssh <master-node>
ETCDCTL_API=3 etcdctl snapshot save /opt/cluster1.db \
--endpoints=https://192.22.104.17:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
Note
Here's a quick tip. In the exam, you won't know if what you did is correct or not, as in the practice tests in this course.
You must verify your work yourself. For example, if the question is to create a pod with a specific image, you must run the kubectl describe pod command to verify the pod is created with the correct name and correct image.